Rows: 3,393
Columns: 61
$ name <chr> "L1764-2", "L1764-3", "L1764-4", "L1764-5a", "L1764-…
$ sale <chr> "L1764", "L1764", "L1764", "L1764", "L1764", "L1764"…
$ lot <chr> "2", "3", "4", "5", "5", "6", "7", "7", "8", "9", "9…
$ position <dbl> 0.03278689, 0.04918033, 0.06557377, 0.08196721, 0.08…
$ dealer <chr> "L", "L", "L", "L", "L", "L", "L", "L", "L", "L", "L…
$ year <dbl> 1764, 1764, 1764, 1764, 1764, 1764, 1764, 1764, 1764…
$ origin_author <chr> "F", "I", "X", "F", "F", "X", "F", "F", "X", "D/FL",…
$ origin_cat <chr> "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O…
$ school_pntg <chr> "F", "I", "D/FL", "F", "F", "I", "F", "F", "I", "D/F…
$ diff_origin <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ logprice <dbl> 5.8861040, 1.7917595, 2.4849067, 1.7917595, 1.791759…
$ price <dbl> 360.0, 6.0, 12.0, 6.0, 6.0, 9.0, 12.0, 12.0, 24.0, 6…
$ count <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ subject <chr> "L'enfant Jesus", "Homme portant un panier", "L'enfa…
$ authorstandard <chr> "Grimou, Alexis", "Fetti, Domenico", "copy after Dyc…
$ artistliving <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ authorstyle <chr> NA, NA, "copy after", NA, NA, "copy after", NA, NA, …
$ author <chr> "Grimou", "F\x8ety", "copi\x8e d'apr\x8fs Wandeik", …
$ winningbidder <chr> "Unknown", "Unknown", "Unknown", "Unknown", "Unknown…
$ winningbiddertype <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ endbuyer <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ Interm <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ type_intermed <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
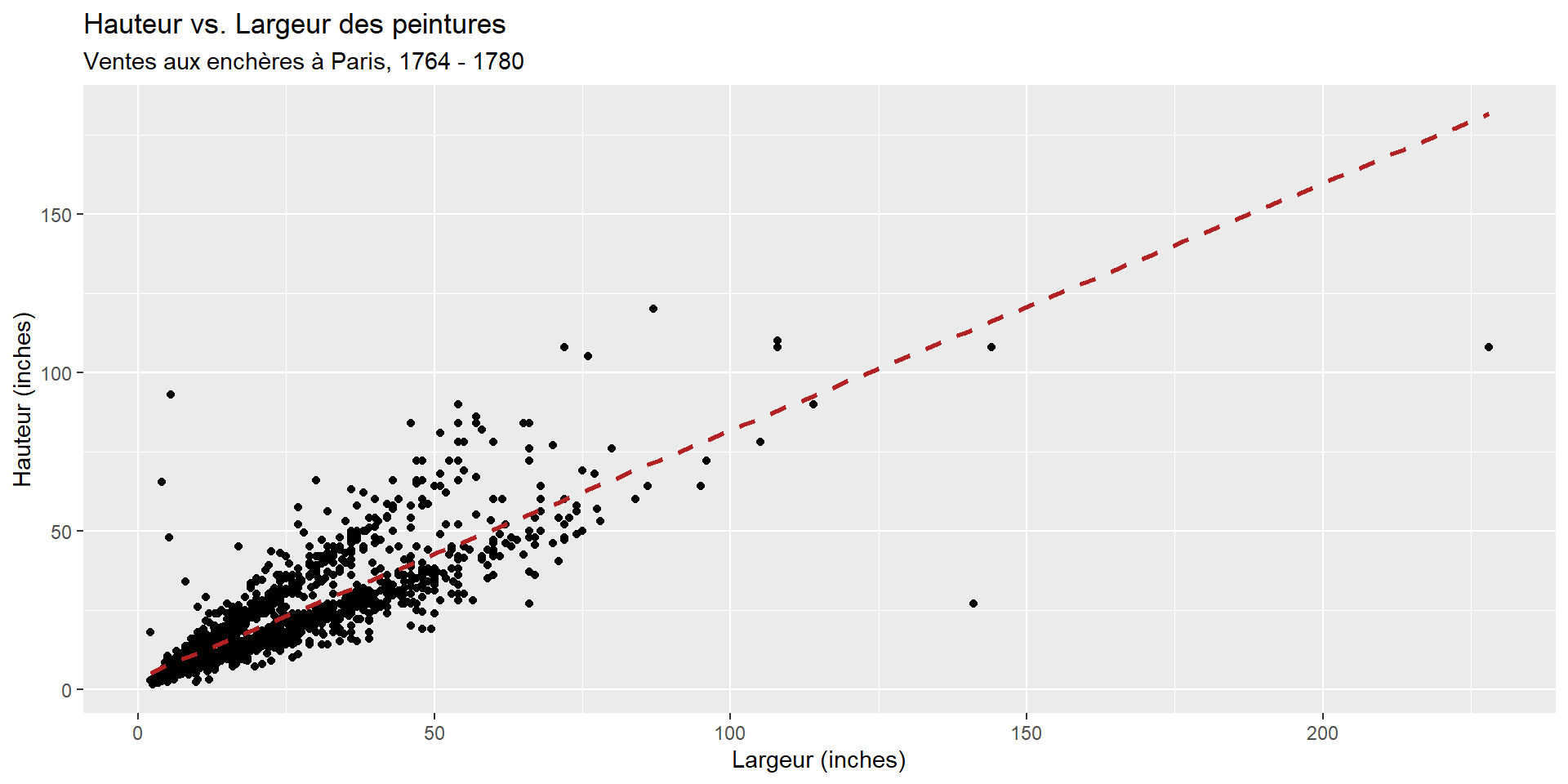
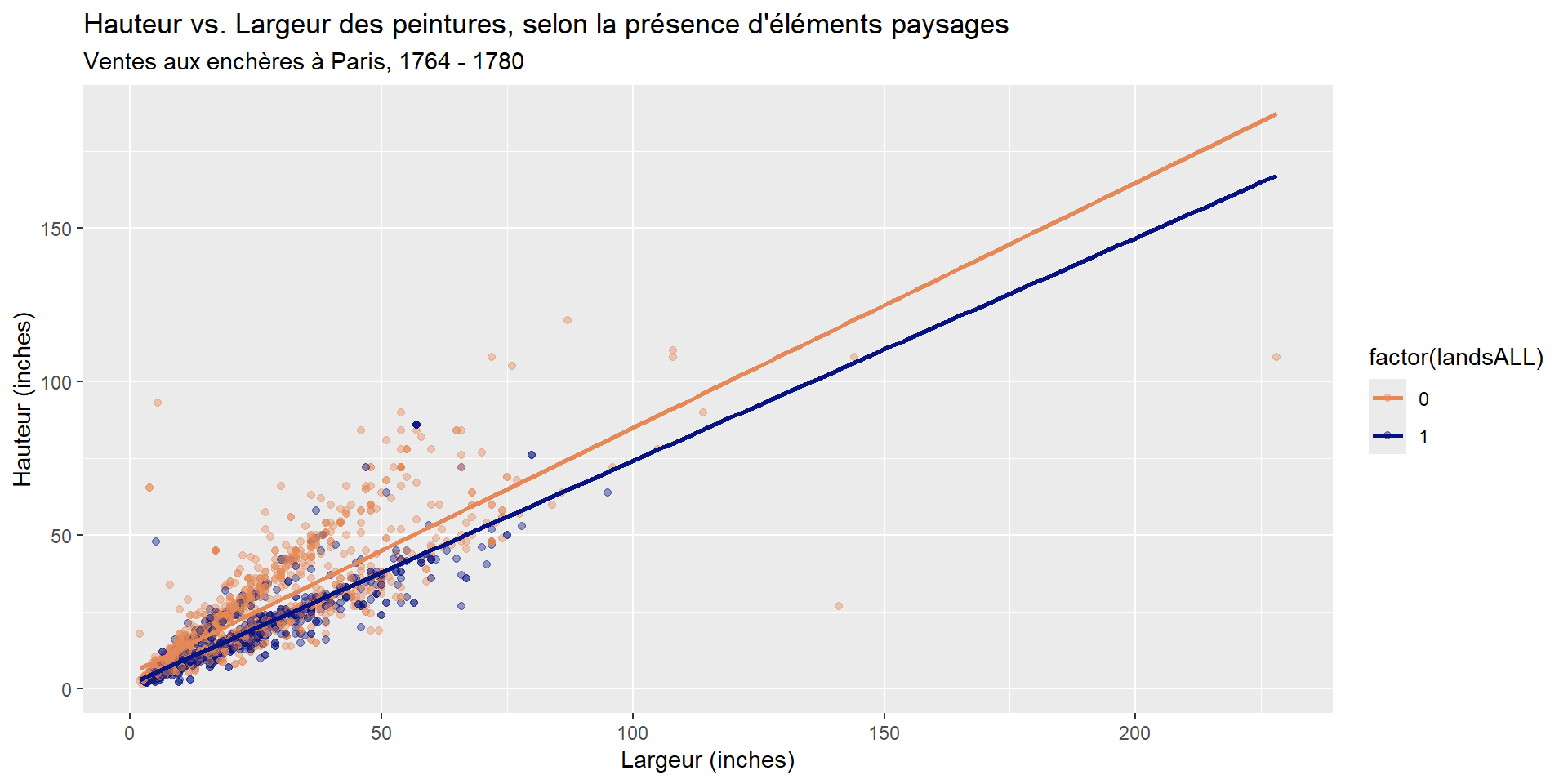
$ Height_in <dbl> 37, 18, 13, 14, 14, 7, 6, 6, 15, 9, 9, 16, 16, 16, 2…
$ Width_in <dbl> 29.5, 14.0, 16.0, 18.0, 18.0, 10.0, 13.0, 13.0, 15.0…
$ Surface_Rect <dbl> 1091.5, 252.0, 208.0, 252.0, 252.0, 70.0, 78.0, 78.0…
$ Diam_in <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ Surface_Rnd <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ Shape <chr> "squ_rect", "squ_rect", "squ_rect", "squ_rect", "squ…
$ Surface <dbl> 1091.5, 252.0, 208.0, 252.0, 252.0, 70.0, 78.0, 78.0…
$ material <chr> "tableau", "toile", "bois", "toile", "toile", "cuivr…
$ mat <chr> "ta", "t", "b", "t", "t", "c", "t", "t", "c", "b", "…
$ materialCat <chr> NA, "canvas", "wood", "canvas", "canvas", "copper", …
$ quantity <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ nfigures <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ engraved <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ original <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ prevcoll <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ othartist <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ paired <dbl> 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1…
$ figures <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ finished <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ lrgfont <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ relig <dbl> 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ landsALL <dbl> 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1…
$ lands_sc <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0…
$ lands_elem <dbl> 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1…
$ lands_figs <dbl> 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1…
$ lands_ment <dbl> 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ arch <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ mytho <dbl> 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ peasant <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ othgenre <dbl> 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ singlefig <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0…
$ portrait <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0…
$ still_life <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ discauth <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ history <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ allegory <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ pastorale <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ other <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…